近年、ChatGPTをはじめとする生成AIの進化によって、私たちの仕事や学び方は大きく変わり始めています。
文章作成、画像生成、音声合成、資料作成、システム開発補助まで、活用範囲は急速に広がっています。
一方で、「そもそも生成AIとは何か?」「AI・機械学習・深層学習・LLMの違いが分かりにくい」と感じる方も多いのではないでしょうか。
本記事では、生成AIの基本的な仕組みから、社会に与えた影響、そして大規模言語モデル(LLM)の概要までをまとめて整理します。
これから生成AIを学びたい方や、業務でどう活かせるかを考えたい方の入門記事として読んでいただければ幸いです。
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/19ae8be4.e750202b.19ae8be5.ab17822b/?me_id=1213310&item_id=18945210&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F2394%2F9784492762394.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")

目次
生成AIとは?
生成AIとは、特定の入力を受け取り、それをもとにテキスト・画像・音声などのオリジナルデータを生み出す技術です。
従来のAIは、「分類する」「予測する」「判定する」といった使われ方が主流でした。
例えば、メールを迷惑メールかどうか判定したり、購買履歴からおすすめ商品を表示したり、不良品を画像から見分けたりする用途です。
それに対して生成AIは、単に判断するだけではなく、新しいコンテンツそのものを作り出せる点が大きな特徴です。
例えば以下のようなことが可能です。
- 指示に応じて文章を書く
- イラストや写真風の画像を生成する
- 音声を作る、変換する
- 要約や翻訳を行う
- プログラムコードや資料案を作る
つまり生成AIは、これまで人間が時間をかけて作っていた「成果物」を、短時間でたたき台として生み出せる技術だといえます。
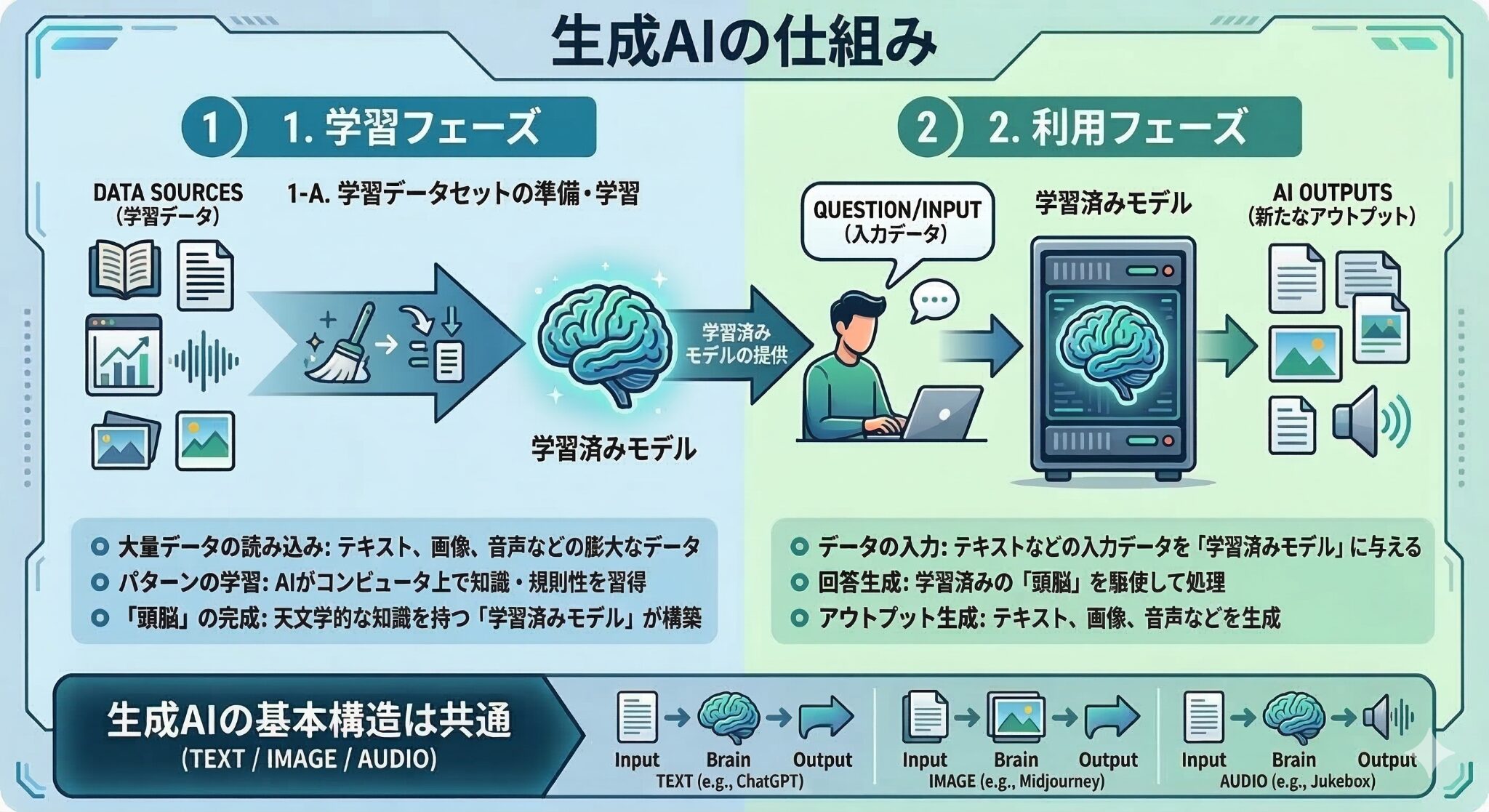
生成AIの基本的な仕組み
生成AIの仕組みは、大きく分けると次の2段階です。
- 開発段階(学習フェーズ)
- 利用段階(推論フェーズ)
開発段階(学習フェーズ)
まずは大量のデータをコンピュータに読み込ませ、パターンや規則性を学習させます。
学習データセットの準備
膨大なデータをそのまま使うのではなく、学習に適した形式へ加工・整理します。
文章、画像、音声など、用途に応じてデータの質を整えることが重要です。
知識のインプット
コンピュータは、人間のように「意味を感覚的に理解する」のではなく、大量データの中からパターンを抽出します。
どの言葉がどの言葉の後に続きやすいのか、どんな特徴が画像の中で重要なのか、といった規則性を蓄積していきます。
学習済みモデルの完成
こうして学習を終えると、入力に対して適切な出力を返せる「学習済みモデル」が完成します。
このモデルは、人間でいえば「頭脳」に近い役割を持つものです。
利用段階(推論フェーズ)
完成した学習済みモデルに対して、ユーザーが指示やデータを入力し、結果を得る段階です。
入力データ
ユーザーが与えるテキストや画像などの入力です。
「この文章を要約して」「会議議事録を作って」「この画像をもとに説明して」といった指示がここに当たります。
生成プロセス
学習済みモデルは、過去に学んだ膨大なパターンを使いながら、入力に対して最も適切そうな出力を組み立てます。
アウトプット
最終的に、テキスト・画像・音声などの新しいコンテンツが生成されます。
補足
この仕組みは、ChatGPTのようなテキスト生成AIだけでなく、画像生成AIや音声生成AIでも基本的には共通しています。
いずれも、大量のデータによる学習が精度を左右するという点が非常に重要です。
プロンプトとは?
生成AIに与える入力のことを、プロンプトと呼びます。
生成AIは非常に高性能ですが、どれだけ優れたモデルであっても、入力が曖昧だと出力も曖昧になりやすいです。
逆に、目的・条件・前提を明確にしたプロンプトを与えることで、回答の質は大きく向上します。
例えば、ただ「要約して」と伝えるよりも、
- 何についての文章か
- どれくらいの長さにしたいか
- 誰向けにまとめたいか
- 箇条書きか文章形式か
まで指定した方が、実務で使いやすい出力になりやすいです。
生成AIを活用するうえで、プロンプトの質は最重要といっても過言ではありません。
だからこそ、今後は「AIを使えるかどうか」だけでなく、AIにどう指示を出すかが大きな差になります。
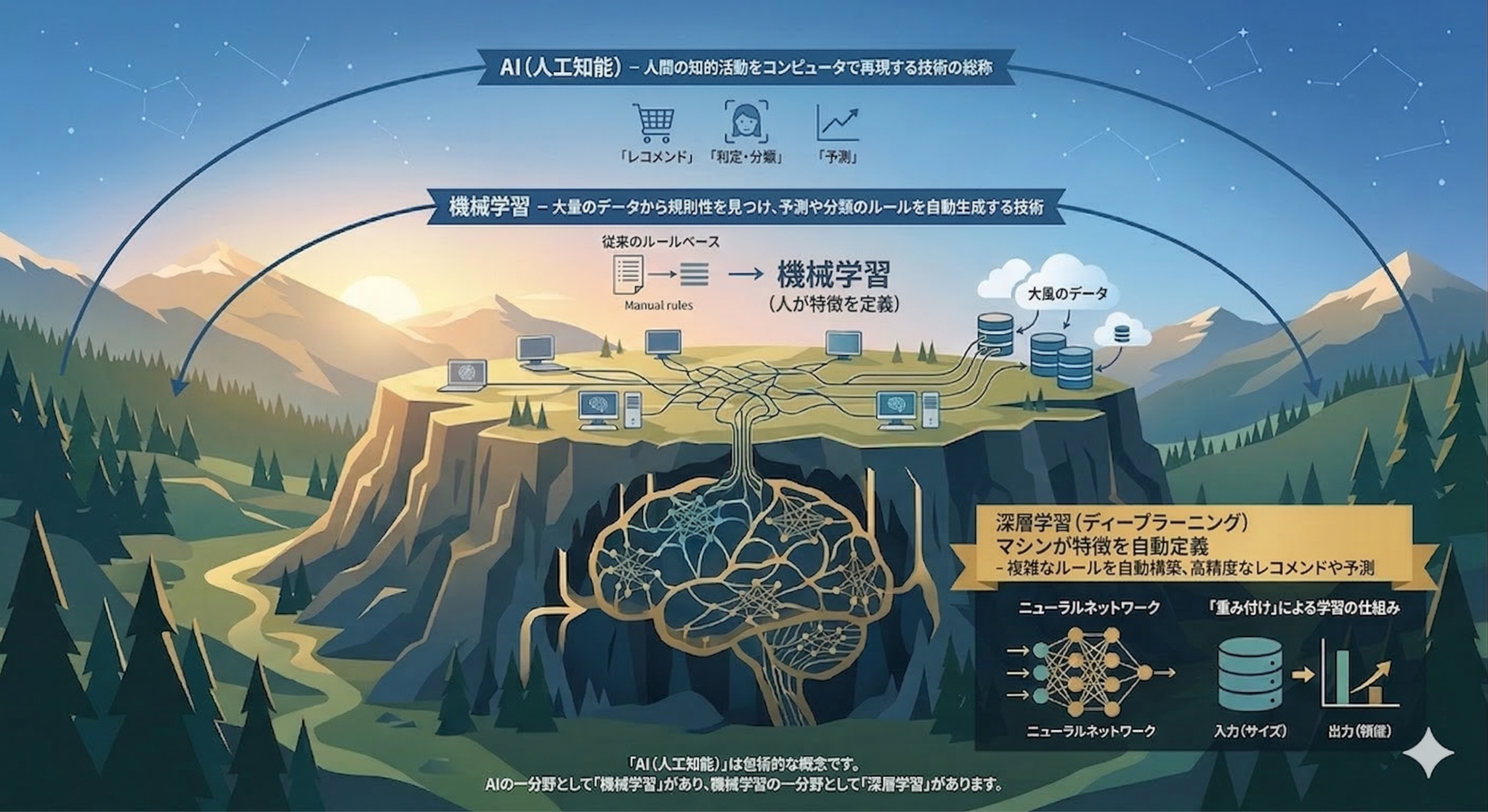
AIとは?
AI(Artificial Intelligence)は、日本語では人工知能と呼ばれます。
人間の知的な活動を、コンピュータで再現しようとする技術の総称です。
主な活用例としては、次のようなものがあります。
- 購買履歴に基づくレコメンド
- 画像による不良品の判定・分類
- 過去データを用いた予測
- 音声認識や自然言語処理
定義はさまざまですが、一般的には人間が行う判断や推測を人工的に実現する技術と捉えると分かりやすいです。
機械学習とは?
AIの中核を担う技術の一つが、機械学習です。
機械学習とは、大量のデータからコンピュータが自ら規則性を見つけ出し、予測や分類のルールを生成する技術です。
従来のルールベース型システムでは、人間が「こういう場合はこう判断する」と明示的にルールを書いていました。
しかし現実のデータは複雑で、すべてのパターンを人間が書き切るのは困難です。
そこで機械学習では、データそのものからルールを学習します。
この考え方によって、人間の手作業では難しい規模と精度で判断が可能になりました。
生成AIの「学習済みモデル」も、この機械学習の考え方の延長線上にあります。
深層学習とは?
深層学習(ディープラーニング)は、機械学習の学習手法の一つです。
膨大なデータから、より複雑で高度なルールを自動で構築することを得意としています。
特に以下のような分野で強みを発揮します。
- 画像認識
- 音声認識
- 自然言語処理
- レコメンド
- 高度な予測
従来手法よりも高い精度を出せるケースが多い一方で、真価を発揮するには大量のデータが必要です。
データが少ない場合は、かえって精度が安定しないこともあります。
そのため、深層学習を業務で活かす際には、アルゴリズムだけでなく、データの量と質をどう確保するかが非常に重要です。
AI・機械学習・深層学習の関係
この3つの関係は、次のように理解すると整理しやすいです。
- AI:包括的な概念
- 機械学習:AIの一分野
- 深層学習:機械学習の一分野
つまり、深層学習はAIの中のさらに一部です。
この関係性を押さえておくと、生成AIの話題も理解しやすくなります。
深層学習(ディープラーニング)の本質
深層学習の本質は、人間の脳の神経回路を模したニューラルネットワークを用いて学習する点にあります。
「重み付け」による学習の仕組み
AIは入力データの各要素に対して、「正解を導くうえでどれくらい重要か」を判断し、それぞれに重みを割り当てます。
例えば画像認識であれば、
- 体の大きさ
- 耳の形
- 模様
- 色
- 輪郭
といった特徴が、判定にどう影響するかを内部で調整していきます。
初期段階
最初の重みはランダムに近く、判断精度も高くありません。
学習過程
大量のデータを読み込む中で、誤差を少しずつ修正しながら重みを微調整していきます。
この反復を繰り返すことで、AIは人間が明示的にルールを与えなくても、重要な特徴を自ら見つけられるようになります。
この仕組みが、生成AIや画像認識AIの高精度を支える土台です。
生成AIが社会に与えた影響
生成AIは、単なる新技術ではなく、社会やビジネスの前提を変えつつある存在です。
特に影響が大きいのは、次の3点だと感じます。
膨大なデータの処理
人間が短時間で読み切れない量の情報を整理し、要約し、構造化できるようになりました。
これは調査、分析、文書作成、問い合わせ対応など、多くの領域でインパクトがあります。
創造性とイノベーションの促進
生成AIは単なる自動化ツールではありません。
アイデア出し、構成案作成、デザインのたたき台作成など、創造的な仕事の初速を大きく上げます。
効率性と生産性の向上
メール文面、提案資料、議事録、コードの雛形などを短時間で作れるため、日々の業務効率は大きく改善します。
特に「ゼロから作る」負担を減らせる点は非常に大きいです。
仕事やビジネスはどう変わるのか
生成AIの普及によって、仕事の価値の置かれ方も変わっていく可能性があります。
単純作業の価値は相対的に下がる
定型的で反復可能な作業は、今後ますますAIに代替・補助されやすくなります。
その結果、単純作業そのものの希少性は下がっていくでしょう。
「全体を見渡して管理する人」の価値が上がる
一方で重要になるのは、AIが出した結果を使いながら、目的に沿って全体を設計・管理できる人です。
つまり、個別作業の実行者というより、流れを設計するマネージャー的役割の重要性が増す可能性があります。
一次情報の価値が高まる
今後さらに価値を持つのは、自社独自のデータや最新の研究成果など、公開されていない一次情報です。
なぜなら、生成AIは一般公開された情報には比較的アクセスしやすい一方で、企業独自の文脈や現場データこそが差別化要因になるからです。
例えば企業が、
- 市場動向
- 消費者行動
- 製品性能
- 問い合わせ履歴
- 社内ノウハウ
といった一次情報を蓄積し、それを生成AIと組み合わせれば、より競争優位性の高いサービスを作れる可能性があります。
生成AIとどう付き合っていくべきか
生成AIを効果的に使うには、AIの知識量や処理能力に頼るだけでは不十分です。
大事なのは、人間が使用目的と方向性を明確に定義することです。
生成AIは強力ですが、あくまで目的達成のためのサポートツールです。
何を目指すのか、どこまでをAIに任せるのか、最終成果物をどう評価するのかは、人間が担う必要があります。
特に重要なのは、次の姿勢だと思います。
- AIの出力をうのみにしない
- 目的に照らして使える形へ整える
- 最終判断は人間が行う
- 文脈や背景事情は人間が補う
AIを「魔法の箱」として扱うのではなく、優秀だが指示と評価が必要なパートナーとして捉えることが大切です。
生成AI時代に求められる知識・スキル
今後は、単にツールを触れること以上に、AIと協働するためのスキルが求められます。
プロンプトエンジニアリング力
AIに対して、目的・条件・制約・期待値を明確に伝える力です。
曖昧な依頼ではなく、質の高い指示を設計する力が重要になります。
ハードスキル
ハードスキルとは、特定の職業や業務に関連する知識・技術です。
例えば、開発、インフラ、会計、法務、営業、マーケティングなど、各専門領域の知識がこれに当たります。
生成AIが普及しても、専門領域の理解が不要になるわけではありません。
むしろ、専門知識がある人ほどAIをうまく使えるようになります。
ソフトスキル
ソフトスキルとは、人間関係を築き、効果的にコミュニケーションを取るための能力です。
例えば、
- 相手の意図をくみ取る力
- 説明する力
- 調整する力
- 課題を定義する力
- 合意形成する力
などが含まれます。
生成AIがどれだけ発達しても、最終的に「誰のために、何を、どう実現するか」を決めるのは人間です。
その意味で、ソフトスキルの重要性はむしろ高まると考えています。
大規模言語モデル(LLM)とは?
大規模言語モデル(LLM:Large Language Models)とは、その名の通り、大規模な量の自然言語を学習したモデルです。
ここでいう「モデル」とは、学習したデータをもとに、入力に対する出力を生成するためのルールを備えたプログラム・システムのことです。
少し難しく聞こえるかもしれませんが、シンプルに言えば、
事前に大量の文章を学習し、その知識を使って入力に対する自然な出力を返す仕組み
と理解すれば十分です。
ChatGPTのような対話型AIは、このLLMを中核として動いています。
ユーザーの質問や指示に対して、学習済みの知識と文脈理解を使いながら、自然な文章を生成します。
企業におけるLLM活用例
LLMは、企業のさまざまな業務で活用が進んでいます。
代表的な例を挙げると、次のようなものがあります。
AIチャットボット
社内外からの問い合わせに自動対応する用途です。
FAQ対応や一次受付の自動化により、サポート業務の効率化が期待できます。
システム開発補助
コードのたたき台作成、レビュー補助、設計の壁打ち、エラー原因の整理などに役立ちます。
開発者の生産性向上につながる代表的な領域です。
資料作成
議事録、提案書、説明資料、報告書などのドラフト作成に活用できます。
ゼロから作る負担を軽減し、構成検討にも役立ちます。
まとめ
生成AIは、単なる流行のテクノロジーではなく、すでに仕事やビジネスの進め方を変え始めている重要な存在です。
今回の内容を整理すると、ポイントは以下の通りです。
- 生成AIは、入力をもとに新しいコンテンツを生み出す技術
- 仕組みは「学習フェーズ」と「推論フェーズ」に分かれる
- 活用の質を左右するのがプロンプト
- AIの中に機械学習があり、その中に深層学習がある
- 深層学習は重み付けを調整しながら高精度な判断を実現する
- 生成AIは社会や仕事の進め方に大きな影響を与えている
- 今後はプロンプト力、専門知識、ソフトスキルの組み合わせが重要
- LLMは企業において幅広い活用余地を持つ
生成AIは、使うだけなら誰でも触れます。
しかし、本当に価値を出せるかどうかは、人間が目的を定義し、文脈を与え、最終判断できるかにかかっています。
これからの時代は、「AIに仕事を奪われるか」ではなく、AIを使ってどれだけ価値を拡張できるかが問われるのだと思います。
![[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]](https://hbb.afl.rakuten.co.jp/hgb/19ae8be4.e750202b.19ae8be5.ab17822b/?me_id=1213310&item_id=21770921&pc=https%3A%2F%2Fthumbnail.image.rakuten.co.jp%2F%400_mall%2Fbook%2Fcabinet%2F3463%2F9784295023463_1_3.jpg%3F_ex%3D240x240&s=240x240&t=picttext "[商品価格に関しましては、リンクが作成された時点と現時点で情報が変更されている場合がございます。]")